
Revolutionizing document integration with Docs2KG: transforming heterogeneous data into unified knowledge graphs.
A paper review of GraphRAG: Design Patterns, Challenges, and Recommendations
Source: arxiv
Project repo: github
Docs2KG introduces a novel framework to extract and unify information, including text, table, image etc. from various unstructured documents.
from the article
Overview
Docs2KG introduces a novel framework to extract and unify information from various unstructured documents, such as emails, web pages, PDFs, and Excel files. This system dynamically generates a knowledge graph to represent key information, enabling efficient querying and exploration. Unlike traditional methods limited to specific domains, Docs2KG offers a flexible solution adaptable to various document types and structures.
Key Concepts and Definitions
- Large Language Models (LLMs): AI models trained on extensive text data to understand and generate human-like text.
- Knowledge Graph (KG): A structured representation of knowledge using nodes (entities) and edges (relationships).
- Heterogeneous Data: Data originating from various sources and formats, requiring integration for unified analysis.
Limitations and Problems of Existing Methods:
- Domain-Specific Focus: Traditional methods are often tailored to specific domains, limiting their adaptability.
- Static Schemas: Pre-designed schemas can restrict flexibility and scalability.
- Manual Processing: Existing approaches frequently require significant manual effort to integrate and process diverse data sources.
Approaches:
Docs2KG Framework:
- Entity Extraction: Utilizes LLMs to identify entities and relationships in diverse documents.
- Dynamic Graph Construction: Generates knowledge graphs on-the-fly, accommodating various document structures and content types.
- Unified Querying: Enables efficient querying and exploration across integrated document data lakes.
Comparison to Existing Methods:
- Flexibility: Unlike static schema-based methods, Docs2KG adapts to various document formats dynamically.
- Scalability: The framework supports large-scale data integration without extensive manual intervention.
- Domain Independence: Applicable across different domains due to its adaptable design.
Experiments
- Docs2KG Architecture:
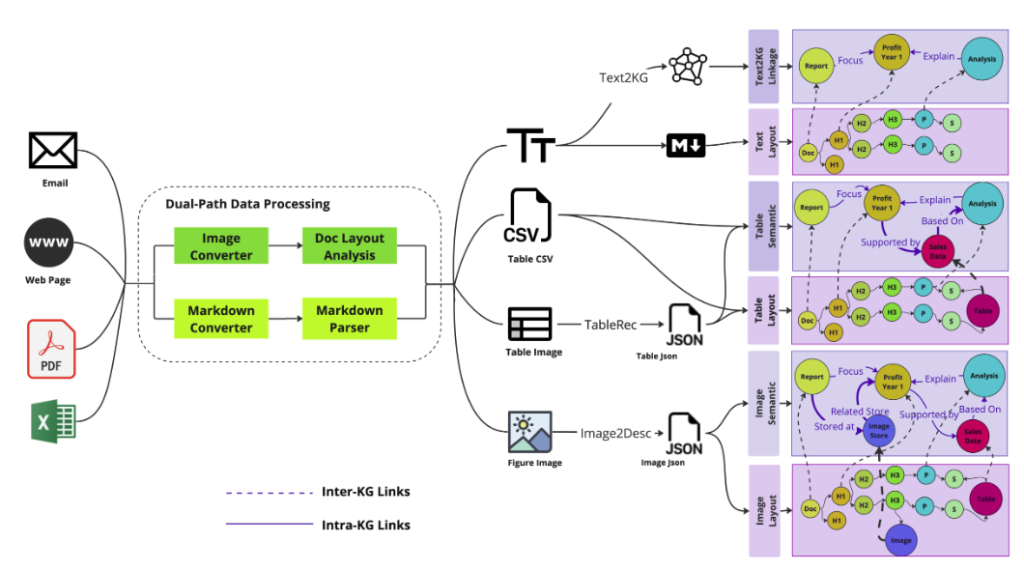
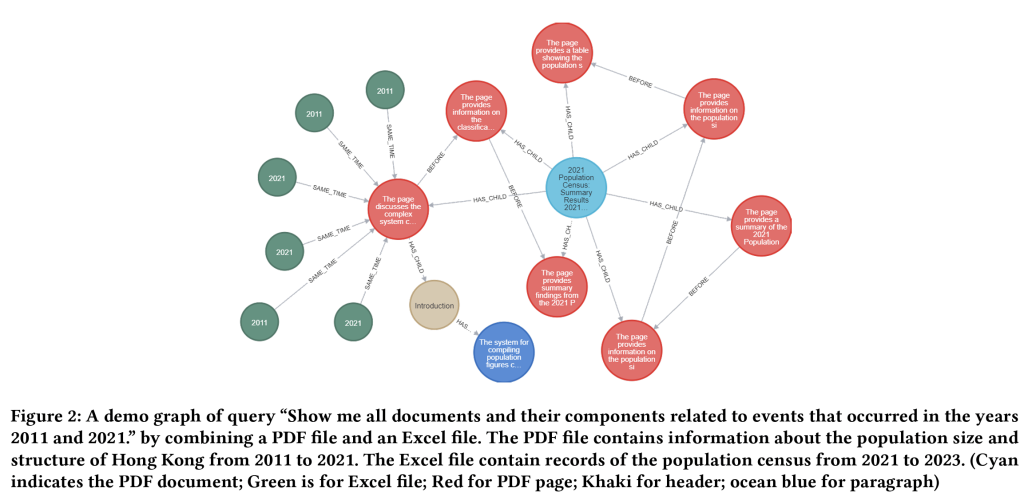
2. Sample graph
Comparisons:
To be added.
Conclusion:
Docs2KG represents a significant advancement in integrating heterogeneous documents into unified knowledge graphs. By leveraging large language models and dynamic graph construction, this framework enhances data querying and exploration, making it a versatile tool for diverse domains.
For a deeper dive into this innovative research, read the full paper here.


